
I recently had someone ask me why the COPY command is more performant than INSERT INTO. While coming up with an answer, I discovered I was starting from a deficient: I didn’t know how COPY works under the hood. Trying to come up with an answer was at best a guess. Through this post, I hope to narrow that knowledge gap and help myself and others get a deeper understanding of my favorite database.
This post will focus primarily on the Postgres psql implementation when performing a COPY command and will stop short of diving into the internals of Postgres’ API layer, libpq. libpq is a set of library functions that allow client programs to pass queries to the PostgreSQL backend server.1
I will start by going over what the COPY command is, how psql packages data to send to libpq, and dive into the C function in Postgres that implements the data transfer. This post will also serve as a background primer for understanding how INSERT INTO works, but only through examining how queries are sent to Postgres.
I had previously thought that COPY was somehow special, perhaps by opening a direct file connection to the underlying data table to achieve the speed COPY does - but that’s not the case. As we’ll see, COPY in psql works by buffering data and utilizing a special code path to transmit data to the libpq API. One of the best parts of Postgres (or open source in general) is that we can look at the source code & documentation, so we’ll be diving right into some C code. Let’s get started.
What even is the COPY command?
Postgres provides two primary ways of inserting data into a table:
-
INSERT INTOand, -
COPY.
To insert data using INSERT INTO, imagine we have a users table with id,name, and email:
CREATE TABLE users (
id INT,
name VARCHAR(100),
email VARCHAR(255)
);
To populate this table with data, we can execute a SQL statement to insert our users:
INSERT INTO users(id, name, email) VALUES
(1, 'John Doe', 'john.doe@example.com'),
(2, 'Jane Smith', 'jane.smith@example.com');
An alternative approach than the above is to utilize the COPY FROM command. To use COPY, we first must create a users.csv file that contains the following data:
1,John Doe,john.doe@example.com
2,Jane Smith,jane.smith@example.com
Then, by executing the following SQL command, we can load the data via COPY:
COPY users(id, name, email)
FROM 'data.csv' DELIMITER ',' CSV;
Alternatively, you can execute this via psql:
psql \copy users(id, name, email) FROM 'data.csv' DELIMITER ',' CSV;
When bulk loading large amounts of data, COPY is significantly faster than any other method. Generally around ~250k rows of data is where the speed of INSERT INTO becomes too slow and I resort to writing a COPY command.
Many database systems with SQL-esque dialects also support some form of COPY, including Redshift, Snowflake, CockroachDB, MySQL (via LOAD DATA), and plenty of others. Certain systems like Snowflake allow you to load not just from a filepath, but also from Amazon S3, Google Cloud Storage, or Microsoft Azure. Database drivers (like Psycopg2 & Pyscopg3) implement support for COPY like so:
users = [(1, "John Doe", "john.doe@example.com"), (2, "Jane Smith", "jane.smith@example.com")]
with cursor.copy("COPY users (id, name, email) FROM STDIN") as copy:
for user in users:
copy.write_row(user)
However, for the purposes of our discussion, I’ll be limiting myself to the COPY FROM command in Postgres which uses the FILE type in C.
How psql transfers data to libpq
When executing a valid SQL query command (i.e., COPY, SELECT ... FROM, INSERT INTO ...), Postgres will rely on sending the command to libpq, the API to Postgres. To effectively communicate, Postgres will encode the command according to the message protocol that libpq uses. There are a variety of different message types and formats supported by libpq. For the case of a SQL query that the user enters, the payload will consist of the following elements:
- Byte1(‘Q’) (Identifies the message as a simple query.)
- Int32 (Length of message contents in bytes, including self.)
- String (The query string itself)
Imagine we ask for a simple request, such as select 1; - this gets encoded as the following message:
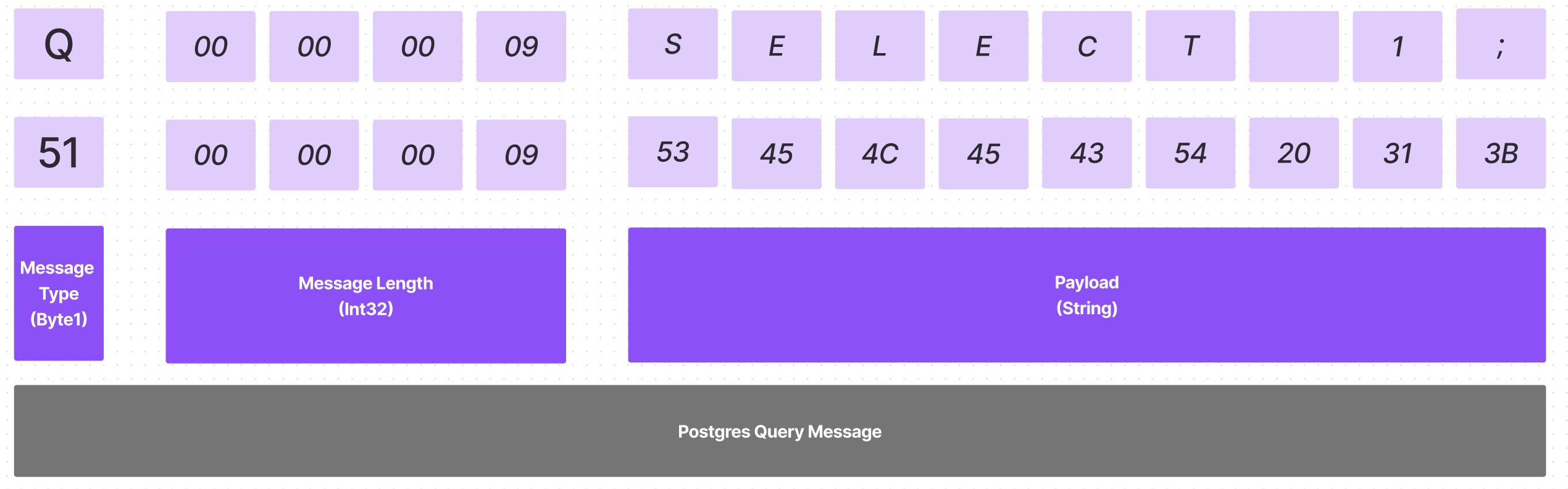
After encoding the request, the message gets placed into an outbound buffer. This buffer serves to minimize the number of round-trip communications that need to occur. Once the buffer is full or is being flushed2, the current buffer of messages is sent to libpq via a function call. As part of the return, Postgres will receive a result back, as well as metadata information about the result status to the invoker.
There are quite a few statuses a result could have:
typedef enum
{
PGRES_EMPTY_QUERY = 0, /* empty query string was executed */
PGRES_COMMAND_OK, /* a query command that doesn't return
* anything was executed properly by the
* backend */
PGRES_TUPLES_OK, /* a query command that returns tuples was
* executed properly by the backend, PGresult
* contains the result tuples */
PGRES_COPY_OUT, /* `COPY` Out data transfer in progress */
PGRES_COPY_IN, /* `COPY` In data transfer in progress */
PGRES_BAD_RESPONSE, /* an unexpected response was recv'd from the
* backend */
PGRES_NONFATAL_ERROR, /* notice or warning message */
PGRES_FATAL_ERROR, /* query failed */
PGRES_COPY_BOTH, /* `COPY` In/Out data transfer in progress */
PGRES_SINGLE_TUPLE, /* single tuple from larger resultset */
PGRES_PIPELINE_SYNC, /* pipeline synchronization point */
PGRES_PIPELINE_ABORTED /* Command didn't run because of an abort
* earlier in a pipeline */
} ExecStatusType;
When a COPY ... FROM STDIN command is sent, libpq will return a result status of PGRES_COPY_IN3. Postgres will check for this status, invoke HandleCopyResult and suquently invoke handleCopyIn, which is where the interesting work happens.
How does handleCopyIn work?
handleCopyIn is a workhorse responsible for consuming the FILE stream, streaming the data to libpq, and finalizing the COPY. There’s a lot of code to break down in handleCopyIn.
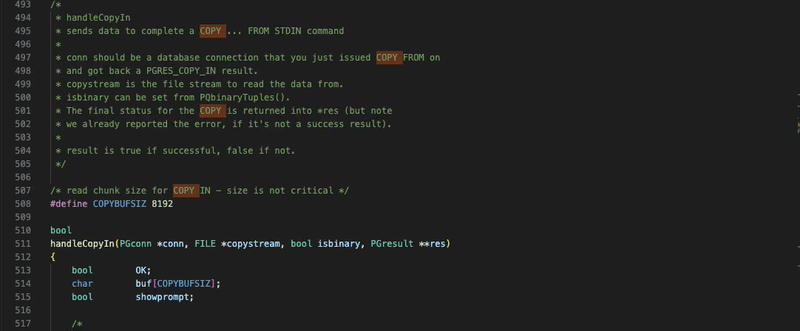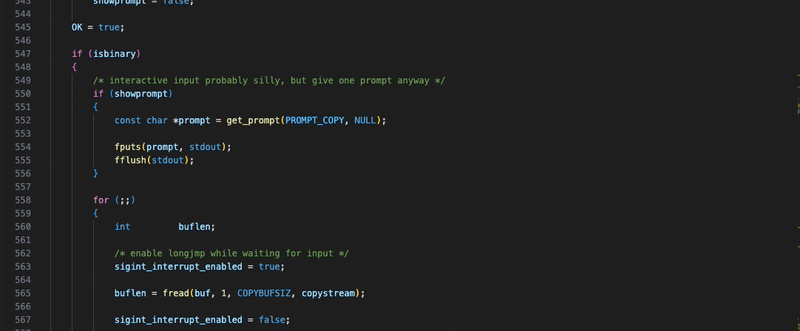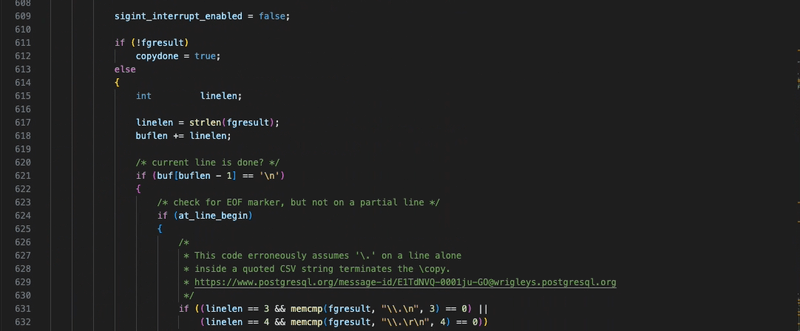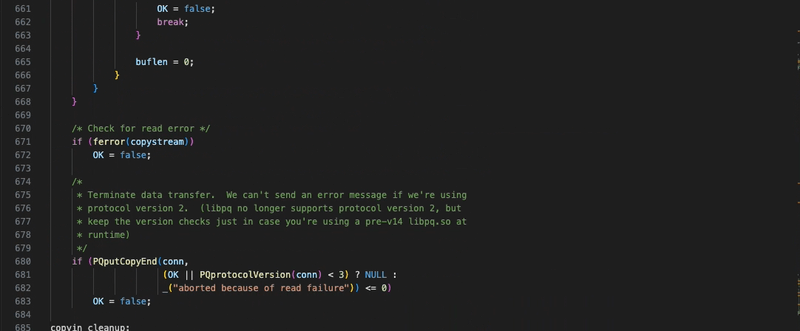
For our purposes, we’ll focus our attention on L592-L668. There’s quite a bit of handling for scenarios such as if the input is interactive, if we’re copying in binary, or if there’s a signal interrupt. To aid the reader, I’ve copied the pertinent section behind this code block (though I suggest cloning and reading along, you get better highlighting),
handleCopyIn(PGconn *conn, FILE *copystream, bool isbinary, PGresult **res)
/* read chunk size for COPY IN - size is not critical */
#define COPYBUFSIZ 8192
bool
handleCopyIn(PGconn *conn, FILE *copystream, bool isbinary, PGresult **res)
{
bool OK;
char buf[COPYBUFSIZ];
bool showprompt;
/*
* Nick Benthem Note - I've truncated the beginning half of the function
* to focus on the core COPY mechanic.
*/
bool copydone = false;
int buflen;
bool at_line_begin = true;
/*
* In text mode, we have to read the input one line at a time, so that
* we can stop reading at the EOF marker (\.). We mustn't read beyond
* the EOF marker, because if the data was inlined in a SQL script, we
* would eat up the commands after the EOF marker.
*/
buflen = 0;
while (!copydone)
{
char *fgresult;
if (at_line_begin && showprompt)
{
const char *prompt = get_prompt(PROMPT_COPY, NULL);
fputs(prompt, stdout);
fflush(stdout);
}
/* enable longjmp while waiting for input */
sigint_interrupt_enabled = true;
fgresult = fgets(&buf[buflen], COPYBUFSIZ - buflen, copystream);
sigint_interrupt_enabled = false;
if (!fgresult)
copydone = true;
else
{
int linelen;
linelen = strlen(fgresult);
buflen += linelen;
/* current line is done? */
if (buf[buflen - 1] == '\n')
{
/* check for EOF marker, but not on a partial line */
if (at_line_begin)
{
/*
* This code erroneously assumes '\.' on a line alone
* inside a quoted CSV string terminates the \copy.
* https://www.postgresql.org/message-id/E1TdNVQ-0001ju-GO@wrigleys.postgresql.org
*/
if ((linelen == 3 && memcmp(fgresult, "\\.\n", 3) == 0) ||
(linelen == 4 && memcmp(fgresult, "\\.\r\n", 4) == 0))
{
copydone = true;
}
}
if (copystream == pset.cur_cmd_source)
{
pset.lineno++;
pset.stmt_lineno++;
}
at_line_begin = true;
}
else
at_line_begin = false;
}
/*
* If the buffer is full, or we've reached the EOF, flush it.
*
* Make sure there's always space for four more bytes in the
* buffer, plus a NUL terminator. That way, an EOF marker is
* never split across two fgets() calls, which simplifies the
* logic.
*/
if (buflen >= COPYBUFSIZ - 5 || (copydone && buflen > 0))
{
if (PQputCopyData(conn, buf, buflen) <= 0)
{
OK = false;
break;
}
buflen = 0;
}
}
/* Check for read error */
if (ferror(copystream))
OK = false;
/*
* Terminate data transfer. We can't send an error message if we're using
* protocol version 2. (libpq no longer supports protocol version 2, but
* keep the version checks just in case you're using a pre-v14 libpq.so at
* runtime)
*/
if (PQputCopyEnd(conn,
(OK || PQprotocolVersion(conn) < 3) ? NULL :
_("aborted because of read failure")) <= 0)
OK = false;
}Let’s go through the above function handleCopyIn at a high level. The general process the function follows is:
-
Instantiate
bufandbuflenas a buffer.-
bufis an array which can store at most 8192 bytes of data. -
buflenrepresents the current amount of data we’ve loaded intobuf. - We’ll continuously write data to
buf, and flush2 the data frombufas we go.
-
-
Read data into our buffer via
fgets.- Instantiate
fgresultto check if we’re at the end of our stream.fgresultwill be either&buf[buflen], iffgetsis successful, or null if there’s an error or end of file. - We load data from the
copystreamIO and store the results intobuf. - Ensure we don’t overflow our buffer by only reading in
COPYBUFSIZ - buflencharacters at a time.
- Instantiate
-
Increment our buffer and see if we’re at the end of a line.
- We increment our buffers length by the number of characters we just wrote in.
- There’s edge case checking for end of file (EOF) characters.
-
Flush2 our buffer if we have enough data, or are done with the file.
- We do this by sending the current connection, the buffer, and the length of data in the buffer (
buflen) toPQputCopyData`. -
PQputCopyDatareturns 1 if successful, 0 if data couldn’t be sent, or -1 if an error occurs.
- We do this by sending the current connection, the buffer, and the length of data in the buffer (
- Repeat until done.
- Finalize transmission by calling
PQputCopyEnd.
How do PQputCopyData and PQputCopyEnd work?
In the previous function handleCopyIn, we’re continuously iterating through the FILE input. PQputCopyData handles the flushing2 of the buffer while ensuring that messages are encoded and sent out to libpq. As mentioned previously, to communicate with libpq we must construct a message. The COPY functionality has a unique d message type that libpq uses to receive COPY data from Postgres. To create a CopyData message, the message needs to have the following elements:
- Byte1(‘d’) (Identifies the message as COPY data.)
- Int32 (Length of message contents in bytes, including self.)
- Byte [n] (Data that forms part of a COPY data stream).
This message type looks very similar to the Q message type we encountered when we sent a SELECT 1;, but rather than send the string of a query, we send the data we’ve read from the FILE.
You can see this behavior in the code from PQputCopyData here:
if (nbytes > 0)
{
/*
* Try to flush any previously sent data in preference to growing the
* output buffer. If we can't enlarge the buffer enough to hold the
* data, return 0 in the nonblock case, else hard error. (For
* simplicity, always assume 5 bytes of overhead.)
*/
if ((conn->outBufSize - conn->outCount - 5) < nbytes)
{
if (pqFlush(conn) < 0)
return -1;
if (pqCheckOutBufferSpace(conn->outCount + 5 + (size_t) nbytes,
conn))
return pqIsnonblocking(conn) ? 0 : -1;
}
/* Send the data (too simple to delegate to fe-protocol files) */
if (pqPutMsgStart('d', conn) < 0 ||
pqPutnchar(buffer, nbytes, conn) < 0 ||
pqPutMsgEnd(conn) < 0)
return -1;
}
An important implementation note is that we never perform additional processing on the d messages. The only validation we receive from libpq is that a given message is received - we do no other validation until the end. In essence, we’re continuously sending messages as fast as we can read them in and transmit them. This is great - we have lower overhead, but once we hit the end of our FILE, we will need to inform libq that we’re done performing our copy. This is where PQputCopyEnd comes into place. After the FILE has been full read from, Postgres will send a message to libpq indicating that the COPY is complete (via c message), or the COPY has failed (via f message).
if (errormsg)
{
/* Send COPY FAIL */
if (pqPutMsgStart('f', conn) < 0 ||
pqPuts(errormsg, conn) < 0 ||
pqPutMsgEnd(conn) < 0)
return -1;
}
else
{
/* Send COPY DONE */
if (pqPutMsgStart('c', conn) < 0 ||
pqPutMsgEnd(conn) < 0)
return -1;
}
Conclusion
As we can see, Postgres COPY works by emitting many messages to libpq to transmit data from a FILE via continuously flushing a buffer. Once all messages have been received successfully, Postgres will emit a special message letting libpq know that the COPY is complete.
I plan on doing another post on how systems like psycopg handle the IO buffer. There are ways in python to utilize the COPY command and feed the STDIN as a python StringIO buffer. I’d like to dig more into how a C FILE reference is created on the server to utilize the above code. I plan to also do more more digging on the libpq side of this operation, including how the data is written to the WAL and processed. My current theory is that libpq will have special code to handle the buffered input, but I’m not sure right now.
Thanks for reading - let me know if this was helpful or if I missed anything ![]() .
.
Edits:
- 2023-08-18 - Updated the introduction to clarify this post focuses on the
\copycommand issued bypsql, not the backendCOPY. Thank you sitharus and terom! Also fixed a typo (thanks Diablo3)
-
https://www.postgresql.org/docs/current/libpq.html ↩
-
Flushing refers to evacuating a buffer and moving the data somewhere else. My mental model is to think of data as a liquid, and we’re filling a sink. We continuously load up the same sink, but have different liquid in the sink each time. When the sink is about to overflow, we “flush” the data - taking data that’s in our sink and moving that data to a new location. We then allow our sink to refill with new, potentially different data. We never move the sink, just the liquid in the sink. ↩ ↩2 ↩3 ↩4
-
You might notice there’s also a
PGRES_COPY_OUTcommand that can be used to offload SQL output to a file, but we’ll ignore that for now. ↩