
I’ve seen a lot of people confused about the difference between the KubernetesExecutor and the KubernetesPodOperator - they similarly named and both use Kubernetes Pods, yet very different in how they run, so the goal of this post is to lay out the differences and help you decide which to use.
If you haven’t decided yet why you want to use Kubernetes - check out this great post by Jessica Laughlin which helps explain the concepts of containerization in your data workflows.
Now that you’ve decided to use Kubernetes (yay!) - you’ll hit your first major decision point in architecting your ETL pipelienes - do you use the Kubernetes Executor, or the Kubernetes Pod Operator? I highly recommend using the Kubernetes Executor over deploying individual Kubernetes Pods, but first let’s cover what each of the two do:
How the Kubernetes Executor works
The Kubernetes executor creates a new pod for each and every task using (by default, but overrideable) the image specified in airflow.cfg: i.e.,
[kubernetes]
worker_container_repository = your.docker.registry/your_image
worker_container_tag = yourTag
With this - each and every task that gets generated by the Executor creates a new Kubernetes pod with the image you specify running a seperate Airflow instance with the same SQL backend for results - the task is then ran in the Webserver of the spawned pod.
The task pod will communicate directly with the SQL backend for your Airflow instance and manage updating the status of the SQL backend’s results. This alleviates the pressure on the main scheduler / webserver instance since the main scheduler is only required to check that a pod was created and sanity checks. I.e., if the task is listed as running, but no Kubernetes pod is running, killing the task and rerunning a new kubernetes pod.
When the worker pod runs, a new Airflow instance is instantiated and the code that is being asked (whether shell, python, sql, etc.) is run on the worker Airflow Webserver instance as a LocalExecutor.
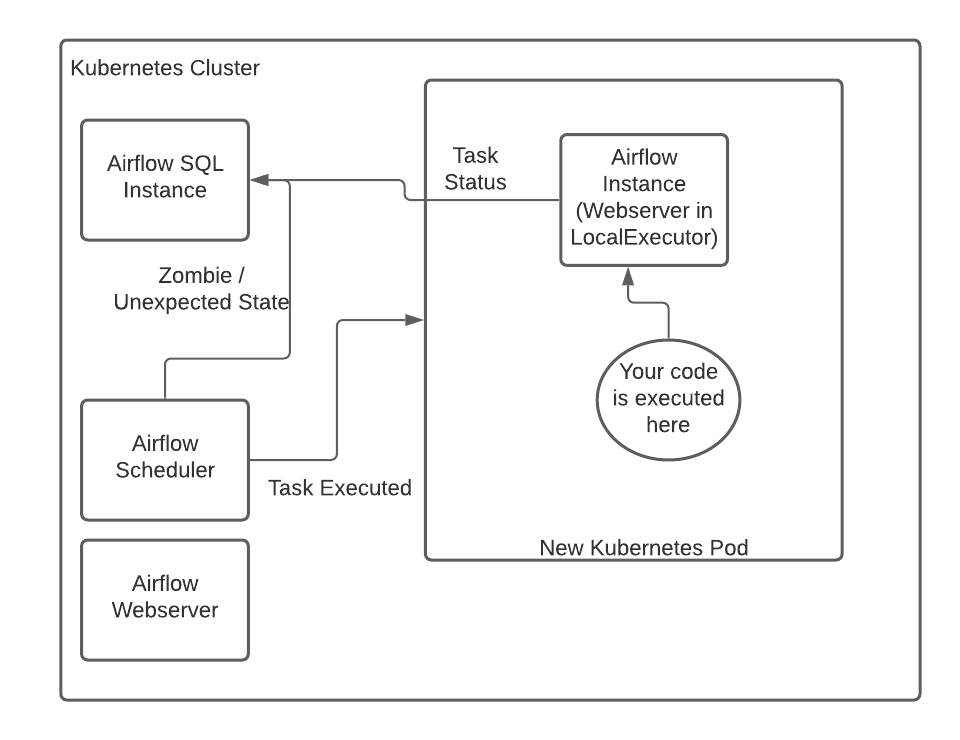
You can have this be the same image as you run your scheduler with - in this case, the default docker image you run is the same between the workers (that run tasks), the scheduler, and the webserver. However - you’re not forced to use the same image as your scheduler and webserver - you can inject whatever image you want - as long as airflow is installed on the image. For instance - this is an entirely valid Operator that will use the put_your_image_here image as the base.
hello_word = BashOperator(task_id = 'hello world',
bash_command = "echo 'hello world'",
executor_config= {"KubernetesExecutor": {
"image": "your_image_with_airflow"
}
}
)
How the Kubernetes Pod Operator works
The Kubernetes Pod Operator can be used with any executor, including the Kubernetes Executor. For the purpose of this section, we’ll explain as if the scheduler is a Local Executor.
Executing the Pod Operator creates a task that spawns a Kubernetes pod in the namespace and cluster you ask for. This uses the entrypoint of the given Docker container, or if you specify the entrypoint in Airflow, the new entrypoint. This allows you to run simple jobs like sh 'hello world' very easily. The local scheduler receives the exit code from the worker pod and registers
the status into the SQL Backend.
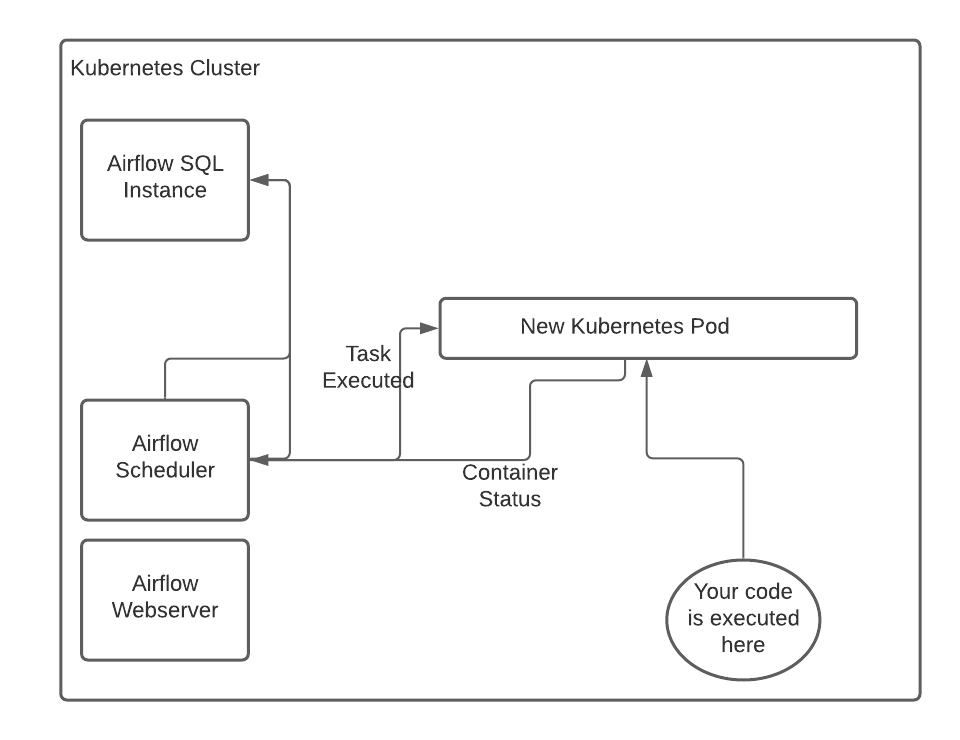
The pod that gets spawned does not have to have Airflow installed in the image, which makes it a good option for running jobs from another team that may not care about Airflow, but just cares about orchestration
What if I use both the Kubernetes Executor and the Kubernetes Pod operator?
This is where it gets redundant and sub-optimal in the current state of Airflow. When you use the combination of the two - you actually launch two pods - one for the worker that contains the scheduler (this comes from the KubernetesExecutor) which then needs to spawn another Kubernetes Pod from within that pod. You could theoretically spawn in two different Kubernetes Clusters with this configuration (the image being in one, and the pod being in another. )
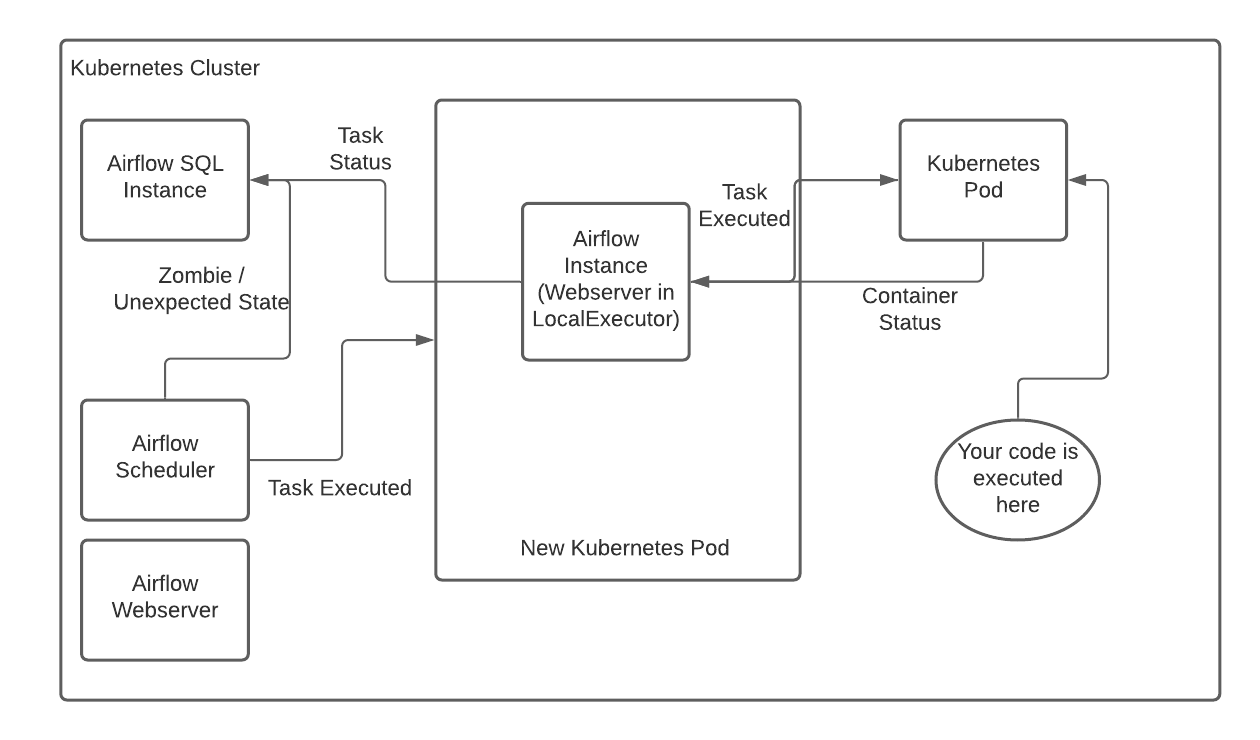
In this case, the pod that gets spawned from the first worker will return a result, and the first worker’s airflow instance will record the result. Overall, this is undesirable but sometimes necessary. The Airflow instance of the new Kubernetes Pod is underutilized.
Why I recommend Kubernetes Executor
Unless you have a lot of existing Docker code, with already built out centralized logging systems, you should probably use the Kubernetes Executor.
Airflow has native operators for many use cases
Need a python operator? Done. Need a SFTP to 3 operator? Just configure what others built.
Airflow has both native operators and community operators. One of my favorite operators - the Great Expectations Operator is ready to use if you use Airflow with the Kubernetes Executor. If you only use Airflow as an orchestrator, you miss out on the community effort.
You can still run arbitrary Docker images.
If you have a specific Docker image you want to run from a seperate team, you can still use the KubernetesPodOperator, you just pay a small penalty for the double pods created.
With the KEDA Executor, more improvements will come to get the best of both worlds.
Data scientists and analysts don’t want to deal with Docker containers
If you use a folder to contain your source code, your data scientists / analysts can write native Python, R, and SQL without worrying about logging, connections, or any other Data Engineering efforts. By prepackaging the connections you can focus less on efficient docker containers and more on business impacting code. Executing code turns into using an operator, rather than desiging a docker container and entry point.
By running a “heavy” docker container as your Docker image that contains libraries preinstalled for Data Science and Analytics, you can avoid having to teach data scientists about dependencies and docker image maintenance - just modify the python, SQL, or R code and they can start developing code - your data engineer can worry about the depencies. If you happen to run into a particularly poorly behaving dependency in your image - you can spin off a specific job with its own set of dependencies using the executor_config option, or using the KubernetesPodOperator.
Conclusion
In my experience running Airflow at scale, it’s very rare you need to run arbitrary Docker containers, and when you do you can pay the small performance penalty until the new KEDA or enhanced KubernetesExecutor removes the double-step.
If you’re interested in getting started - there’s helm charts for Airflow you can use. If you aren’t comfortable launching your own Kubernetes cluster right now, check out hosted offerings such as Astronomer.io - they provide both hosted solutions where you don’t need to worry about Kubernetes cluster maintenance as well as enterprise Kubernetes installs.